Tutorial¶
Introduction¶
Textbrewer is designed for the knowledge distillation of NLP models. It provides various distillation methods and offers a distillation framework for quickly setting up experiments.
TextBrewer currently is shipped with the following distillation techniques:
Mixed soft-label and hard-label training
Dynamic loss weight adjustment and temperature adjustment
Various distillation loss functions
Freely adding intermediate features matching losses
Multi-teacher distillation
…
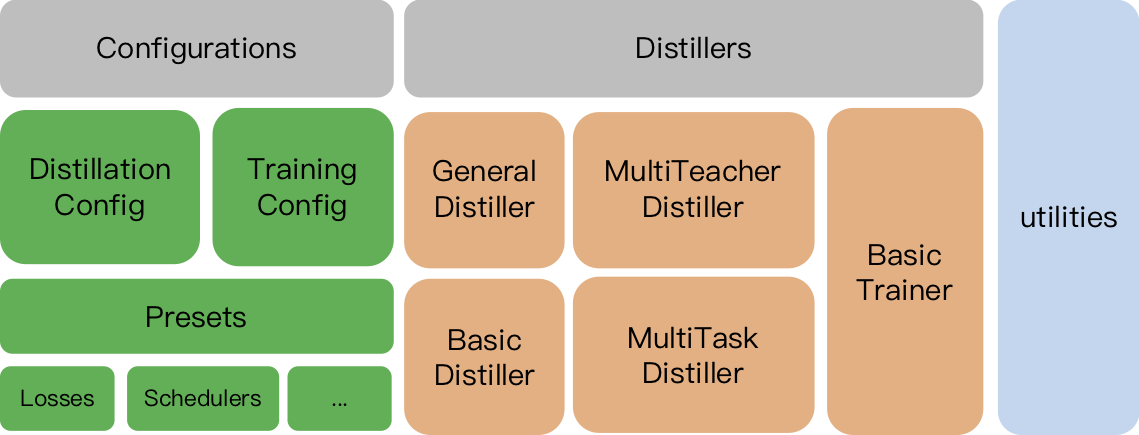
TextBrewer includes:
Distillers: the cores of distillation. Different distillers perform different distillation modes.
Configurations and presets: Configuration classes for training and distillation, and predefined distillation loss functions and strategies.
Utilities: auxiliary tools such as model parameters analysis.
Architecture¶
Installation¶
Requirements
Python >= 3.6
PyTorch >= 1.1.0
TensorboardX or Tensorboard
NumPy
tqdm
Transformers >= 2.0 (optional, used by some examples)
Install from PyPI
pip install textbrewer
Install from the Github source
git clone https://github.com/airaria/TextBrewer.git pip install ./textbrewer
Workflow¶
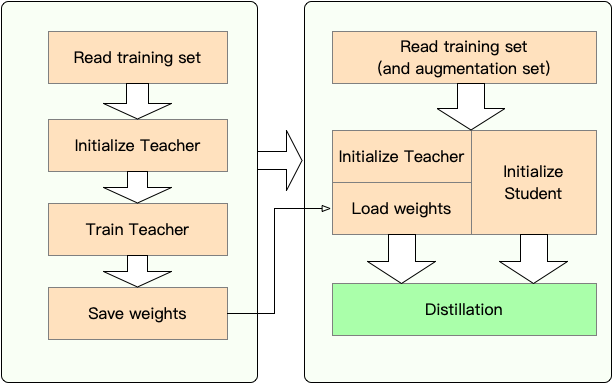
To start distillation, users need to provide
the models (the trained teacher model and the un-trained student model).
datasets and experiment configurations.
Stage 1: Preparation:
Train the teacher model.
Define and initialize the student model.
Construct a dataloader, an optimizer, and a learning rate scheduler.
Stage 2: Distillation with TextBrewer:
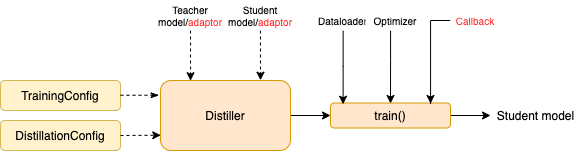
Construct a
TraningConfigand aDistillationConfig, initialize a distiller.Define an adaptor and a callback. The adaptor is used for the adaptation of model inputs and outputs. The callback is called by the distiller during training.
Call the :
trainmethod of the distiller.
Quickstart¶
Here we show the usage of TextBrewer by distilling BERT-base to a 3-layer BERT.
Before distillation, we assume users have provided:
A trained teacher model
teacher_model(BERT-base) and a to-be-trained student modelstudent_model(3-layer BERT).a
dataloaderof the dataset, anoptimizerand a learning rate builder or classscheduler_classand its args dictscheduler_dict.
Distill with TextBrewer:
import textbrewer
from textbrewer import GeneralDistiller
from textbrewer import TrainingConfig, DistillationConfig
# Show the statistics of model parameters
print("\nteacher_model's parametrers:")
result, _ = textbrewer.utils.display_parameters(teacher_model,max_level=3)
print (result)
print("student_model's parametrers:")
result, _ = textbrewer.utils.display_parameters(student_model,max_level=3)
print (result)
# Define an adaptor for interpreting the model inputs and outputs
def simple_adaptor(batch, model_outputs):
# The second and third elements of model outputs are the logits and hidden states
return {'logits': model_outputs[1],
'hidden': model_outputs[2]}
# Training configuration
train_config = TrainingConfig()
# Distillation configuration
# Matching different layers of the student and the teacher
# We match 0-0 and 8-2 here for demonstration
distill_config = DistillationConfig(
intermediate_matches=[
{'layer_T':0, 'layer_S':0, 'feature':'hidden', 'loss': 'hidden_mse','weight' : 1},
{'layer_T':8, 'layer_S':2, 'feature':'hidden', 'loss': 'hidden_mse','weight' : 1}])
# Build distiller
distiller = GeneralDistiller(
train_config=train_config, distill_config = distill_config,
model_T = teacher_model, model_S = student_model,
adaptor_T = simple_adaptor, adaptor_S = simple_adaptor)
# Start!
with distiller:
distiller.train(optimizer, dataloader, num_epochs=1, scheduler_class=scheduler_class, scheduler_args=scheduler_args, callback=None)
Examples¶
Examples can be found in the examples directory of the repo:
examples/random_token_example : a simple runnable toy example which demonstrates the usage of TextBrewer. This example performs distillation on the text classification task with random tokens as inputs.
examples/cmrc2018_example (Chinese): distillation on CMRC 2018, a Chinese MRC task, using DRCD as data augmentation.
examples/mnli_example (English): distillation on MNLI, an English sentence-pair classification task. This example also shows how to perform multi-teacher distillation.
examples/conll2003_example (English): distillation on CoNLL-2003 English NER task, which is in the form of sequence labeling.
examples/msra_ner_example (Chinese): This example distills a Chinese-ELECTRA-base model on the MSRA NER task with distributed data-parallel training(single node, muliti-GPU).
FAQ¶
Q: How to initialize the student model?
A: The student model could be randomly initialized (i.e., with no prior knowledge) or be initialized by pre-trained weights. For example, when distilling a BERT-base model to a 3-layer BERT, you could initialize the student model with RBT3 (for Chinese tasks) or the first three layers of BERT (for English tasks) to avoid cold start problem. We recommend that users use pre-trained student models whenever possible to fully take advantage of large-scale pre-training.
Q: How to set training hyperparameters for the distillation experiments?
A: Knowledge distillation usually requires more training epochs and a larger learning rate than training on the labeled dataset. For example, training SQuAD on BERT-base usually takes 3 epochs with lr=3e-5; however, distillation takes 30~50 epochs with lr=1e-4. The conclusions are based on our experiments, and you are advised to try on your own data.
Q: My teacher model and student model take different inputs (they do not share vocabularies), so how can I distill?
A: You need to feed different batches to the teacher and the student. See Feed Different batches to Student and Teacher, Feed Cached Values.
Q: I have stored the logits from my teacher model. Can I use them in the distillation to save the forward pass time?
A: Yes, see Feed Different batches to Student and Teacher, Feed Cached Values.
Known Issues¶
Multi-label classification is not supported.
Citation¶
If you find TextBrewer is helpful, please cite our paper :
@InProceedings{textbrewer-acl2020-demo,
author = "Yang, Ziqing and Cui, Yiming and Chen, Zhipeng and Che, Wanxiang and Liu, Ting and Wang, Shijin and Hu, Guoping",
title = "{T}ext{B}rewer: {A}n {O}pen-{S}ource {K}nowledge {D}istillation {T}oolkit for {N}atural {L}anguage {P}rocessing",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations",
year = "2020",
publisher = "Association for Computational Linguistics"
}