Core Concepts¶
Conventions¶
Model_Tan instance oftorch.nn.Module, the teacher model that to be distilled.Model_S: an instance oftorch.nn.Module, the student model, usually smaller than the teacher model for model compression and faster inference speed.optimizer: an instance oftorch.optim.Optimizer.scheduler: an instance of a class undertorch.optim.lr_scheduler, allows flexible adjustment of learning rate.dataloader: data iterator, used to generate data batches. A batch can be a tuple or a dictfor batch in dataloader: # if batch_postprocessor is not None: batch = batch_postprocessor(batch) # check batch datatype # passes batch to the model and adaptors
Batch Format(important)¶
Foward conventions: each batch to be passed to the model should be a dict or tuple:
if the batch is a
dict, the model will be called asmodel(**batch, **args);if the batch is a
tuple, the model is called asmodel(*batch, **args).
Hence if the batch is not a dict, users should make sure that the order of each element in the batch is the same as the order of the arguments of model.forward. args is used for passing additional parameters.
Users can additionaly define a batch_postprocessor function to post-process batches if needed. batch_postprocessor should take a batch and return a batch. See the explanation on train method of Distillers for more details.
Since version 0.2.1, TextBrewer supports more flexible inputs scheme: users can feed different batches to student and teacher, or feed the cached values to save the forward pass time. See Feed Different batches to Student and Teacher, Feed Cached Values.
Configurations¶
TrainingConfig: configurations related to general deep learning model training.DistillationConfig: configurations related to distillation methods.
Distillers¶
Distillers are in charge of conducting the actual experiments. The following distillers are available:
BasicDistiller: single-teacher single-task distillation, provides basic distillation strategies.GeneralDistiller(Recommended): single-teacher single-task distillation, supports intermediate features matching. Recommended most of the time.MultiTeacherDistiller: multi-teacher distillation, which distills multiple teacher models (of the same task) into a single student model. This class doesn’t support Intermediate features matching.MultiTaskDistiller: multi-task distillation, which distills multiple teacher models (of different tasks) into a single student.BasicTrainer: Supervised training a single model on a labeled dataset, not for distillation. It can be used to train a teacher model.
User-Defined Functions¶
In TextBrewer, there are two functions that should be implemented by users: callback() and adaptor() .
-
callback(model, step) → None¶ At each checkpoint, after saving the student model, the callback function will be called by the distiller. callback can be used to evaluate the performance of the student model at each checkpoint.
Note
If users want to do an evaluation in the callback, remember to add
model.eval()in the callback.- Parameters
model (torch.nn.Module) – the student model
step (int) – the current training step
-
adaptor(batch, model_inputs) → dict¶ It converts the model inputs and outputs to the specified format so that they can be recognized by the distiller. At each training step, batch and model outputs will be passed to the adaptor; adaptor reorganize the data and returns a dict.
The functionality of the adaptor is shown in the figure below:
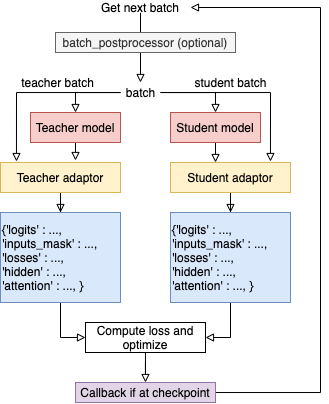
- Parameters
batch – the input batch to the model
model_outputs – the outputs returned by the model
- Return type
dict
- Returns
a dictionary that may contain the following keys and values:
’logits’ :
List[torch.Tensor]ortorch.TensorThe inputs to the final softmax. Each tensor should have the shape (batch_size, num_labels) or (batch_size, length, num_labels).
’logits_mask’:
List[torch.Tensor]ortorch.Tensor0/1 matrix, which masks logits at specified positions. The positions where mask==0 won’t be included in the calculation of loss on logits. Each tensor should have the shape (batch_size, length).
’labels’:
List[torch.Tensor]ortorch.TensorGround-truth labels of the examples. Each tensor should have the shape (batch_size,) or (batch_size, length).
Note
logits_mask only works for logits with shape (batch_size, length, num_labels). It’s used to mask along the length dimension, commonly used in sequence labeling tasks.
logits, logits_mask and labels should either all be lists of tensors, or all be tensors.
’losses’ :
List[torch.Tensor]It stores pre-computed losses, for example, the cross-entropy between logits and ground-truth labels. All the losses stored here would be summed and weighted by hard_label_weight and added to the total loss. Each tensor in the list should be a scalar.
’attention’:
List[torch.Tensor]List of attention matrices, used to compute intermediate feature matching loss. Each tensor should have the shape (batch_size, num_heads, length, length) or (batch_size, length, length), depending on what attention loss is used. Details about various loss functions can be found at Intermediate Losses.
’hidden’:
List[torch.Tensor]List of hidden states used to compute intermediate feature matching loss. Each tensor should have the shape (batch_size, length, hidden_dim).
’inputs_mask’ :
torch.Tensor0/1 matrix, performs masking on attention and hidden, should have the shape (batch_size, length).
Note
These keys are all optional:
If there is no inputs_mask or logits_mask, then it’s considered as no masking.
If not there is no intermediate feature matching loss, you can ignore attention and hidden.
If you don’t want to add loss of the original hard labels, you can set
hard_label_weight=0in theDistillationConfigand ignore losses.If logits is not provided, the KD loss of the logits will be omitted.
labels is required if and only if
probability_shift==True.You shouldn’t ignore all the keys, otherwise the training won’t start :)
In most cases logits should be provided, unless you are doing multi-stage training or non-classification tasks, etc.
Example:
''' Suppose the model outputs are: logits, sequence_output, total_loss class MyModel(): def forward(self, input_ids, attention_mask, labels, ...): ... return logits, sequence_output, total_loss logits: Tensor of shape (batch_size, num_classes) sequence_output: List of tensors of (batch_size, length, hidden_dim) total_loss: scalar tensor model inputs are: input_ids = batch[0] : input_ids (batch_size, length) attention_mask = batch[1] : attention_mask (batch_size, length) labels = batch[2] : labels (batch_size, num_classes) ''' def SimpleAdaptor(batch, model_outputs): return {'logits': (model_outputs[0],), 'hidden': model.outputs[1], 'inputs_mask': batch[1]}
Feed Different batches to Student and Teacher, Feed Cached Values¶
Feed Different batches¶
In some cases, student and teacher read different inputs. For example, if you distill a RoBERTa model to a BERT model, they cannot share the inputs since they have different vocabularies.
To solve this, one can build a dataset that returns a dict as the batch with keys 'student' and 'teacher'.
TextBrewer will unpack the dict, and feeds batch['student'] to the student and its adaptor, feeds batch['teacher'] to the teacher and its adaptor, following the forward conventions.
Here is an example.
import torch from torch.utils.data import Dataset, TensorDataset, DataLoader class TSDataset(Dataset): def __init__(self, teacher_dataset, student_dataset): # teacher_dataset and student_dataset are normal datasets # whose each element is a tuple or a dict. assert len(teacher_dataset) == len(student_dataset), \ f"lengths of teacher_dataset {len(teacher_dataset)} and student_dataset {len(student_dataset)} are not the same!" self.teacher_dataset = teacher_dataset self.student_dataset = student_dataset def __len__(self): return len(self.teacher_dataset) def __getitem__(self,i): return {'teacher' : self.teacher_dataset[i], 'student' : self.student_dataset[i]} teacher_dataset = TensorDataset(torch.randn(32,3),torch.randn(32,3)) student_dataset = TensorDataset(torch.randn(32,2),torch.randn(32,2)) tsdataset = TSDataset(teacher_dataset=teacher_dataset,student_dataset=student_dataset) dataloader = DataLoader(dataset=tsdataset, ... )
Feed Cached Values¶
If you are ready to provide a dataset that returns dict with keys 'student' and 'teacher' like the one above, you can also add a another key 'teacher_cache', which stores the pre-computed outputs from the teacher. Then TextBrewer will treat batch['teacher_cache'] as the output from the teacher and feed it to the teacher’s adaptor. No teacher’s forward will be called.
Here is an example.
import torch from torch.utils.data import Dataset, TensorDataset, DataLoader class TSDataset(Dataset): def __init__(self, teacher_dataset, student_dataset, teacher_cache): # teacher_dataset and student_dataset are normal datasets # whose each element is a tuple or a dict. # teacher_cache is a list of items; each item is the output from the teacher. assert len(teacher_dataset) == len(student_dataset), \ f"lengths of teacher_dataset {len(teacher_dataset)} and student_dataset {len(student_dataset)} are not the same!" assert len(teacher_dataset) == len(teacher_cache), \ f"lengths of teacher_dataset {len(teacher_dataset)} and teacher_cache {len(teacher_cache)} are not the same!" self.teacher_dataset = teacher_dataset self.student_dataset = student_dataset self.teacher_cache = teacher_cache def __len__(self): return len(self.teacher_dataset) def __getitem__(self,i): return {'teacher' : self.teacher_dataset[i], 'student' : self.student_dataset[i], 'teacher_cache':self.teacher_cache[i]} teacher_dataset = TensorDataset(torch.randn(32,3),torch.randn(32,3)) student_dataset = TensorDataset(torch.randn(32,2),torch.randn(32,2)) # We make some fake data and assume teacher model outputs are (logits, loss) fake_logits = [torch.randn(3) for _ in range(32)] fake_loss = [torch.randn(1)[0] for _ in range(32)] teacher_cache = [(fake_logits[i],fake_loss[i]) for i in range(32)] tsdataset = TSDataset(teacher_dataset=teacher_dataset,student_dataset=student_dataset, teacher_cache=teacher_cache) dataloader = DataLoader(dataset=tsdataset, ... )